
venue: ICLR 2020
paper link: here
This paper proposes strategies to pre-train a GNN at node-level and graph-level.
1. Node-Level Pre-training
Node-level pre-training is to use unlabeld data to capture domain knowledge in the graph. Two methods are proposed for node-level pre-training.
1.1 Context Prediction
In this task, subgraphs are used to predict their surrouding graph structures. The goal is to let a pre-trained GNN map nodes appearing in similar structure context have closer embeddings.
K-hop neighborhood of a node v contains all nodes and edges that are at most K-hops away from v in the graph.
Context graph of a node v is a subgraph that is between r1-hops and r2-hops away from v. It is required that r1 < K so that there are context anchor nodes that shared between the neighborhood and the context graph.

An auxiliary GNN called context GNN is used to encode context graphs as fixed-length vectors. The average embedding of context anchor nodes is considered as a fixed-length context embedding. For node v in graph G, its context embedding is 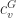
Negative sampling is used to jointly learn the main GNN and the context GNN. The main GNN encodes neighborhoods to obtain node embeddings. The context GNN encodes context graphs to obtain context embeddings. The objective is to predict whether a particular neighborhood and a particular context graph belong to the same node:
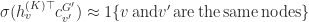
where 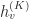

1.2 Attribute Masking
The goal of this task is to capture domain knowledge by learning the regularities of the node-edge attributes distributed over graph structure.
First node/edge attributes are masked , then GNNs are used to predict those attributes based on neighboring structure. For example in Figure 2(b), input node/edge attributes such as the atom types in molecular graphs, are randomly masked and replaced by special indicators. Then GNNs are used to obtain the corresponding node/edge embeddings. Finally a linear model is used to predict the masked label.
2. Graph-Level Pre-training
2.1 Supervised Graph-Level Property Prediction
First graph-level prediction tasks should be defined, then jointly predict a diverse set of supervised labels of individual graphs. However, this actually requires domain knowledge to select appropriate graph-level pretraining tasks, otherwise one may hurt the dowmstream performance(negative tranfer). To alleviate this issue, one strategy is to first do node-level pretraining, since the local node embeedings may be not useful learnd from graph-level pretraining tasks.
2.2 Structure Similarity Prediction
This approach is to pretrain GNNs with tasks like graph edit distance or predicting graph structure similarity. However, finding the ground truth graph distances could be difficult.
