
The paper tries to answer the following questions:
- What are the common attention patterns, how do they change during fine-tuning, and how does that impact the performance on a given task?
- What linguistic knowledge is encoded in self-attention weights of the fine-tuned models and what portion of it comes from the pre-trained BERT?
- How different are the self-attention patterns of different heads, and how important are they for a given task?
Here is link to the code: https://github.com/text-machine-lab/dark-secrets-of-BERT
1. BERT’s self-attention patterns
After manual inspection of self-attention weights for both basic and fine-tuned BERT models, it shows that there are 5 frequently occurring patterns:
- Vertical: mainly corresponds to attention to special BERT tokens [CLS] and [SEP]
- Diagonal: formed by the attention to the previous/following tokens
- Vertical+Diagonal: a mix of the previous two types
- Block: intra-sentence attention for the tasks with two distinct sentences (such as, for example, RTE or MRPC)
- Heterogeneous: highly variable depending on the specific input and cannot be characterized by a distinct structure. (This one is assumed to be more likely to capture interpretable linguistic features.)

400 self-attention weights are manually annotated and it turns out that 30% belongs to “Vertical” class. Then a CNN classifier is trained to estimate the proportion of attention types across different tasks(GLUE benchmark). The results are shown in Figure 2. It seems that s elf-attention map types are consistently repeated across different heads and tasks.

2. Relation-specific heads in BERT
The authors also tested whether the BERT self-atttention can capture different syntactic and semantic relations. Specifically, they examine the semantic role relations in FrameNet and whether the links between two units(frame-evoking lexical units and core frame elements) produce higher attention weights in certain specific heads.
For each link/token pairs, they average the maximum absolute attention weight of the corresponding links of all heads. Figure 3 shows the averaged attention scores over all examples . It suggests that 2 out of 144 heads tend to attend to token pairs with certain relations. An example the attention patterns from two heads is also shown in Figure 3.

3. Change in self-attention patterns after fine-tuning
This section studies how attention per head changes on average due to fine-tuning for each of GLUE tasks . To do this, they calculate the cosine similarity between pre-trained and fine-tuned BERT’s flattened arrays of attention weights. The derived similarities are averaged over all development sets.
From Figure 5 we can see that fine-tuning has the largest impact on the final 2 layers, which inditates that the last two layers encode task-specific features. The lower layers may capture more fundamental and low-level features.

4. Attention to linguistic features
In this experiment, they investigate whether slef-attention patterns that emphasize specific linguistic features are created by fine-tuning BERT. Therefore, they check whether there are vertical stripe patterns corresponding to linguistically interpretable features, and to what extent such features are relevant for solving a given task.
Specifically, attention to nouns, verbs, pronouns, subjects, objects, and
negation words and special BERT tokens are of intetests. For every head, the sum of attention weights assigned to the token of interest is calculated. The sum is normalized by sequence length. If there are multiple tokens of the same type (e.g. several nouns ), the maximum value is taken.
The results show that vertical attention pattern is associated predominantly with attention to [CLS] and [SEP]. Though there are heads that pay increased attention to nouns, objects of predicates and negation. compared with the pre-trained BERT, the weights are negligible compared to [CLS] and [SEP]. Figure 6 shows the attention weights to [SEP] and [CLS] that are averaged over input lengths and per-task dataset examples .

They believe that the stripped attention maps come from pre-trained tasks rather than task-specific fine-tuning.
5. Token-to-token attention
This experiment is complemenraty to previous one. Specifically, tokens of interest(e.g. those have verb-subject relation,noun-pronoun relation) are checked whether they get higher attention weights while [CLS] in the last layer is processed, since this [CLS] is used for final prediction. The features in Section 4 are used.
The found that potential head candidates that prioritize noun-pronoun and verb-subject links coincide with diagonally structured attention maps. One possible reasons is that some tokens with relations are close to each other under the English syntax. Figure 7 shows the attention distribution for [CLS] in the last layer. For majority tasks, [SEP] gets attended the most. They also mention that for some tasks, punctuations get attended similar to [SEP].

6. Disabling self-attention heads
Disabling a head is defined as modifying the attention values of the head to be constant 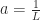
Disabling some heads hurt the performance. However, disabling some heads or disabling a whole layer can improve the results. Figure 8 shows the results of disabling a single head and Figure 9 shows the results of disabling a whole layer.


Comments
- For section 3(section 4.3 in the original paper), it is possible that the phenomena in Figure 5 results from the optimization properties. During the training, will the top layers always obtain larger gradients ? Besides, there is a optimization strategy in https://arxiv.org/pdf/1801.06146.pdf called ” discriminative fine-tuning“, that top layers have larger learning rate. If this strategy is used, it is not surprising that top-layers changes more after fine-tuning.
- I cast a doubt on section 4 (section 4.4 in the original paper), since the authors don’t show the actual results that compare the pre-trained BERT and fine-tuned BERT.)
